

银行数据中心与灾难恢复管理评估
在集中式在线银行系统中,银行具有一个数据中心(DC),该数据中心存储并提供经营该业务所需的银行信息。数据中心是用于容纳计算机系统和相关组件(如电信和存储系统)的设施。它通常包括冗余或备用电源,冗余数据通信连接,环境控制(例如空调,灭火)和安全设备。
灾难恢复是与自然或人为灾难后的组织至关重要的技术基础结构的恢复或延续相关的准备过程,策略和程序。灾难恢复是业务连续性的子集。业务连续性涉及在中断事件中使业务的各个方面保持正常运转的计划,而灾难恢复则侧重于支持业务功能的信息技术(IT)或技术系统。
万一发生灾难,可以更换硬件和网络,并将设施移至新位置。实际上,除数据外,几乎所有公司资产都可以替换。因此,应高度重视保护风险最大,最难替换的资产:数据。数据丢失可能由多种因素造成,例如:人为错误,操作系统或应用程序软件错误,硬件故障,火灾,烟雾或水灾,断电,员工盗窃或欺诈,人为灾难,例如故意破坏,破坏,骇客入侵,病毒和自然灾害,例如地震或飓风。
IT灾难恢复计划并非易事。现代信息系统的复杂性以及技术变化的迅速步伐使得很难确保采取适当的措施。 DC定期处理数千笔交易。内部应用程序总是在开发,修改,集成和淘汰。制定IT灾难恢复计划并使其正确无误是一项日益艰巨的任务。灾难恢复站点(DRS)是组织在灾难,火灾,洪水,恐怖威胁或其他破坏性事件等灾难发生后可以轻松迁移的位置。这是灾难恢复计划和组织更广泛的业务连续性计划的组成部分。
网上银行还执行某种形式的数据备份,而这些银行并不总是能做得很好。由于一些组织的IT人员处理备份的能力有限,因此它们偶尔执行大容量服务器备份,使用传统磁带进行备份,并且通常在一天关闭之后执行任务。这意味着,如果有任何灾难导致需要恢复数据,则银行可以期望恢复的最新数据是前一天晚上的数据。如果银行失去了数小时的资金转帐功能,可能会对业务造成极大损害。银行往往会同时运行许多关键应用程序,因此,尽快恢复在故障点丢失的数据至关重要。结果,需要标准的DC和DRS来连续备份数据,以便基本上实时地捕获更改后的数据,因此,只要文件发生更改,就可以立即对其进行捕获和保护。
不能忽视信息技术的风险。 IT是银行业务不可或缺的一部分,因此有必要持续进行灾难恢复计划。尽管灾难恢复计划的目的是确保灾难后IT服务的恢复,但是IT灾难恢复计划并不是一件容易的事。
国际数据公司(IDC)的研究确定,所有公司中有98%受到计划外停机的不利影响。此外,Gartner Inc.的研究发现,遭受重大数据丢失的组织中有93%在五年内倒闭。 1993年世界贸易中心爆炸案迫使位于该中心的三分之二的公司(147)在1994年内停业。
还发现,SunGard自1978年以来一直支持的170场灾难恢复中,大多数发生在过去10年中。在这些回收中,有45家是银行。当北卡罗来纳州大福克斯社区国家银行由于遭受大洪水袭击而发现其数据中心时,银行业的一次复苏发生在北卡罗来纳州大福克斯。
DC和DRS的建立
在孟加拉国,截至2016年底,有88%的银行通过DC提供集中数据库操作。商业银行的大多数DC都是在过去十年中开发的。 DC和DRS的平均年龄分别为10.5和8.5岁。要在银行部门成功实施DC和DRS,至少需要1年到4年。
DC和DRS的大小
可以看出,DC和DRS的平均面积分别为2596和957平方英尺。 65%的CTO对DC和DRS的大小不满意。他们一直面临着诸如设备的安装和移动,监控甚至为拥堵适当冷却系统的问题。
DC和DRS的位置
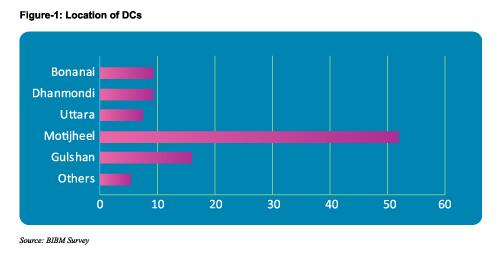
除一些外国银行外,大多数数据中心都在孟加拉国建立。大约66%的CTO声称DC和DRS的位置正确,没有任何风险。相比之下,分别有11%和22%的银行对该地点的风险中等和低感到不满意。在Gulshan建立了大约20%的数据中心,在Motijheel建立了52%,在Uttara建立了8%,在Dhanmondi建立了10%,在Banani建立了10%。大多数外国银行在孟加拉国都设有区域数据中心。已经发现,在高层建筑物中建立DC的风险已引起银行部门的警觉。在高层建筑中已建立了约58%的DC和18%的DRS。尽管所有银行都告知这些建筑物是地震保护的,但它们均未提供有关此问题的任何证据或文件。大约77%的银行甚至没有提及确保建筑物吸收的地震震级(以里氏震级)。对于DRS也发现了同样的情况。银行应在这方面给予更多重视。根据我们的调查,有25%的银行建立了额外的数据中心(ADC),而15%的ADC已在高层建筑中建立。
拥有数据中心的银行也有灾难恢复站点。结果发现,在Uttara,23%的Savar,14%的Dhanmondi,14%的Mohakhali,14%的Mirpur,12%的Gazipur(Tongi)和6%的Jessore设立了23%的灾难恢复站点。数据中心和灾难恢复站点的最低,最高和平均距离分别为5公里,30公里和11.3公里。大约60%的DRS位于距DC 5至9公里的范围内。对于20%的银行,DC到DRS的距离在10到14公里之间;对于10%的银行,距离在25到29公里之间;对于仅10%的银行,距离超过100公里。在孟加拉国银行的CTO中,有38%的人认为该距离是标准的,而62%的人坚决认为该距离不足以避免地震等自然灾害。在单独的地震带中,它应与直流至少相距100公里。此外,有35%的银行计划将其DRS远离数据中心,至少要转移100个。
大约44%的银行还计划在Gazipur,Comilla或Jessore设置第二个DRS,以降低风险。
此外,可以看到只有35%的银行拥有有效维护DC和DRS的认证数据中心设计专家(CDCDP)。
DRS测试
对于集中式在线银行,定期和定期测试DRS是一个重要且至关重要的问题。此类测试可增强在发生灾难时恢复数据的信心和专业知识。只有66%的银行对此进行了测试。其中只有45%的银行每季度进行测试,有15%的银行每半年进行测试,而20%的银行每年进行测试。他们还没有提供有关此问题的文档(范围,计划和测试结果)。而且,总银行中有55%害怕通过随时关闭数据中心来测试灾难恢复站点。这一发现表明该技术的质量和就绪性很差,包括对数据中心和灾难恢复站点的适当管理。
数据中心分类
Uptime Institute已为数据中心建立了四个级别的容错能力,第1级是最低级别,第4级是最高级别,具有完整的多径配电,发电和UPS系统。第1层规定的年度中断时间最长为28.8小时;第2层指定22个小时;第3层指定1.6个小时,第4层指定仅0.4个小时的年度中断,即99.995%的可用性。等级越高,建筑施工和环境设备的投资水平越高。
我们发现57%的DC属于1级,其余43%属于2级。然而,没有一家银行达到第三级或第四级类别。
DC和DRS中的数据库管理
数据库通过银行的CBS直接收集,更新和提供数据。它可以被视为银行信息系统的核心。数据库管理是一项非常重要和负责的工作,因为有关银行业务的所有类型的信息都存储在银行的数据库中。如果发生任何与技术或安全性相关的问题,如果数据库管理员在灾难后未能保护银行的数据或无法重现数据,则银行可能会由于无法获得有关银行交易的信息而失去业务。
在研究中,发现有44%的银行雇用技术人员/专业人士来管理数据库,而没有计算机科学/工程学或相关学科的学术背景。但是他们拥有OCP DBA,MCP DBA等专业证书,平均经验为5年。 12%的数据库管理员仅接受短期课程培训,他们一直在经验不足的银行中提供此类服务。我们还发现,其余44%的银行都拥有适当的数据库管理团队,这些团队具有丰富的知识,并拥有OCP DBA / MCP DBA和计算机科学背景等专业证书,并且具有至少6年至11年的丰富经验。 76%的CTO对维护数据库的团队的绩效感到满意,但24%的人未对此问题做出答复。
高可用性群集是一组计算机,它们支持可以在最短停机时间内可靠利用的应用程序。当系统组件发生故障时,群集可提供连续的服务。如果没有群集,则如果运行特定应用程序的服务器崩溃,则在修复崩溃的服务器之前,该应用程序将不可用。群集通过检测硬件/软件故障并立即在另一个系统上重新启动应用程序而无需管理干预(此过程称为故障转移)来纠正这种情况。对于集中式在线银行,群集服务器可提供高数据可用性,并确保在数据中心中任何服务器出现故障时均能确保流畅的数据服务。
复制是共享信息的过程,以确保冗余资源之间的一致性,从而提高可靠性,容错性或可访问性。如果进行数据复制,则相同的数据将存储在不同位置的多个存储设备上。例如,数据中心可以将其数据复制到灾难恢复站点中。到2016年底,发现只有38%的用户具有实时数据库复制技术。但是,研究结果表明,如果生产数据库服务器出现技术故障,仍有62%的银行可能无法提供数据可访问性。
崩溃时,日志和归档日志文件对数据库非常重要。在这种紧急情况下,如果正确维护存档和日志文件,则数据库的自动恢复过程可能会确保“ 0位”丢失。对于重大灾难或事故,如果数据库和备份文件一起崩溃,则只要可以确保日志和归档日志文件,就可以重建被破坏的数据库。通常,日志文件存储在不同的远程位置,称为“日志多路复用”,“归档”是从数据库开始(或自上次完整备份以来)开始存储所有日志文件的过程,通常存储在远程位置。大约46%的银行拥有日志多路复用架构,只有32%的银行使用日志归档/发送机制。
数据库备份策略有时可确保恢复丢失的数据。如果备份的数据没有正确加密,存储到正确的设备中,进行维护和测试,则可能存在完全恢复数据的风险。即使在最坏的情况下也无法恢复数据。大约44%的银行将其备份的数据保留在DC内部到保管库中。另外22%的银行将其备份数据发送到DRS,并将其保存在机柜中。其余33%的银行将其备份数据放入分支机构内。在银行中,只有21%的银行拥有防火保险库,用于保存备份的存储介质。但是,有15%的银行同意备份数据在偏远地区不受安全保护。测试备份数据是日常工作,可以顺利恢复数据,但是44%的银行避免了此过程,并且遵循此过程的人没有适当的文档。其中有60%的银行每月进行测试,有20%的银行每季度进行测试,其余的银行没有提及有关此问题的时间表。但是,只有22%的备份数据被加密。
数据库管理员是维护银行数据的关键人员。 DBA进行的任何错误或有意的有害活动都可能给银行造成严重损失。在这方面,监视DBA完成的活动是一个重要的问题。只有22%的银行报告说,他们在进行数据库中的任何活动之前已正确监视了DBA。但是他们无法指定如何监视DBA,这表明存在很大的安全漏洞。
定期审核数据库是提供数据库安全性的重要问题。必须进行监视才能知道数据库内部正在发生什么以及参与者是谁。扫描工具,日志记录,事务分析,流量分析,运行状况检查,警报和跟踪文件检查等,是数据库审核的重要组成部分。要求专业人员每天通过软件或报告工具检查上述特征。只有45%的银行由自己的数据库专家定期(每天或每周)进行此操作。 18%的银行每年由外部和内部审计师对数据库进行审计,而9%的银行不对其数据库进行此类审计,而其余28%的银行没有回应。审计数据库系统的银行中有54%报告说审计师有资格审计数据库。另一方面,有46%的银行提到审计师的培训不足以正确完成这项工作。显然,由于审计师的培训不足以发现安全漏洞,这些银行的审计体系较差可能会给数据库安全带来另一风险。但是,有82%的银行定期监视异常的数据库流量。
由于96%的银行从不同的供应商处购买了银行软件,因此数据库的任何更改或修改都高度依赖它们。在这种情况下,银行通常会凭信心向卖方提供数据库管理密码。 18%的银行诚实地报告了这一事实,并且他们对卖方的任何意外数据更改/丢失或不道德行为承担高风险。连接到数据库后,甚至他们也无法监控供应商的工作。但是82%的银行不向供应商提供对数据库的任何直接访问。而是在供应商的帮助下,他们可以在需要时进行任何更改。
物理与环境安全
物理安全涉及提供环境保护措施以及控制对设备和数据的物理访问。适当的保障方法被认为是实用,合理的,并反映了良好的商业惯例。
物理访问控制
要进入DC和DRS,11%的银行需要使用刷卡,33%的感应卡和22%的生物识别技术。大约22%的银行同时使用邻近卡和生物识别技术。此外,有11%的人同时使用刷卡和生物识别技术。大约22%的银行在DC和DRS逗留期间不陪伴供应商,服务提供商,访客和清洁人员。
可靠的电源
大约有22%的建筑物中有DC(由房东设置)的单个发电机,而DRS则为33%。银行已为自己设置了其他生成器。此外,11%的银行在DC中没有自己的双/冗余发生器。他们完全依靠建筑物房东安排的发电机。 DRS为44%。大约11%的银行具有电源设置,该电源设置与DC的生产服务器没有分开。 33%的组在DC内部具有电源设置,但由不防火的分区隔开。大约44%的银行在DC外部但位于同一楼层的空地中设置了电源,而11%的电源单元在DC外部但位于单独的防火室中。还发现11%的银行没有用于DC和DRS的冗余UPS。
消防与控制
根据BB的指南,DC / DRS中发生任何火灾时自动喷火是至关重要的安全措施。所有银行都维护有自动火灾警报系统,烟雾/热上升探测器和自动消防系统。发现有63%的银行将火灾探测器保持在高架地板以下,而36%的银行对汽车火灾报警系统和钻井进行定期测试。尽管所有银行的DC和DRS都有灭火系统,但只有11%的银行提到他们已经对其进行了测试。但是他们没有提交系统的范围,计划和测试结果。
保护DC和DRS的门,墙壁和天花板免受火灾也很重要。发现77%的银行具有耐火墙,55%的银行具有耐火天花板,而77%的银行门是耐火的。但是,只有55%的银行对DC的所有组件(门,墙和天花板)具有完整的防火措施(图5)。尽管BB不允许,但我们发现DC和DRS内部的易燃配件/产品占22%的库。
其他重要问题
大约63%的银行在活动地板下设有水检测系统。大约72%的银行维护双/冗余空调。其中有12%的人已经建立了精密的冷却系统,并为DC维持了正确的热通道/冷通道配置。只有45%的银行具有适当的紧急出口门,以便在发生任何灾难时迅速安全地移除高成本敏感设备。此外,大约33%的银行没有用于DC和DRS操作的专用车辆,而22%的DC没有应急照明装置,而对于DRS则为33%。
业务连续性(BC)和灾难恢复计划(DRP)
恢复是在发生故障或灾难后恢复操作(尤其是数据)的过程。这是很明显的一点,但经常被忽略:能够立即恢复数据对于确保业务连续性至关重要。当大多数公司制定业务连续性计划时,首先要考虑的是通常他们能够使业务重新运行的速度。尽管这是一个至关重要的问题,但这只是恢复方程式的一半。恢复计划的第二部分需要关注组织可以承受的数据丢失量。
发生任何灾难时,灾难恢复计划都将发挥重要作用。只有64%的银行报告说他们有适当的灾难恢复计划。其中66%的DRP被最高机构批准。尽管64%的银行具有DRP,但其中77%的银行没有独立的灾难恢复团队。根据CTO的说法,其余23%的银行的团队规模为8到13,并且没有经过适当的培训。
大多数IT灾难恢复计划指南要么不一致,要么复杂。在这两种情况下,结果都是相同的:组织不准备应对与IT相关的灾难。对于大多数银行来说,都没有找到足够的IT灾难恢复计划来解决IT预算和IT员工人数的问题。但是,准备充分的银行会进行以下七个活动的一些变体:进行IT服务分析,提供员工培训,选择IT灾难识别和通知的方法,定义备份程序,确定异地存储位置,确定恢复程序以及执行持续的活动。保养。大约55%的银行会定期测试其DRP。其中20%的银行每季度进行一次测试,半年进行20%的测试,每年进行60%的测试。但是没有找到与这方面的测试相关的文档。
灾难的经验及其影响
大约44%的银行告知他们经历了中小型灾难。另一方面,有33%的人没有这种经验,而23%的银 行没有回应。火灾(22%组),设备故障(22%组),断电(55%组),网络故障(55%组),软件故障(22%组),用户操作错误(11%组),极端天气(11%的银行),专业人员的丢失(11%的银行),磁盘故障(55%的银行)和病毒攻击(11%的银行)是可提及的灾难。
解决问题平均需要2到72个小时。当然,业务受到严重阻碍。 55%的银行确实在本地/外国供应商的帮助下克服了这些问题,22%的银行在自己的专家的帮助下克服了问题,11%的银行和专家在这两者的帮助下克服了问题。 k 24 lac为Tk。需要2千万克拉才能解决这个问题。
经历灾难的银行对银行业务产生了严重影响。图7显示了灾难对银行业的各种影响。
安全金字塔
为了从DC和DRS提供安全的数据服务,要求CTO从最低到最高类别对因素进行排序:人员,策略,实践,支持系统,网络,硬件和设施。他们对因素进行了排序,因此,我们建立了以下安全构建块,可以遵循以下安全构建块,以最小化银行的DC和DRS操作风险(图9)。在此,安全金字塔每个区块的面积表示与每个因素(人员,政策,…,设施)相关的风险
训练
在IT部门工作时保持最新很重要。为了跟上有关IT的竞争,培训对于银行的生存至关重要。 IT培训的目标是使银行能够有效地管理信息存储,检索和流程。每年,都会开发出更先进的技术系统。计算机,软件和网络必须定期更新。技术部门必须不断意识到这些变化。另外,由于缺乏最新的技术知识,安全性可能受到阻碍。银行有责任定期升级其员工,以提供国内外培训。但这大多数银行都忽略了。大约3%的预算用于培训目的,而66%的IT主管对此问题不满意。大约44%的CTO表示,尽管非常需要,但他们无法为操作DC和DRS的人员提供足够的培训。
BB的作用
关于孟加拉银行在通过DC和DRS降低数据服务风险方面的总体作用的观点,有45%的银行表示非常好,有55%的银行被评为“好”,这要求孟加拉银行发挥更多和高质量的作用。孟加拉银行通常每年访问一次不同商业银行的DC和DRS。所有CTO都认为这还不够;应增加频率以进行严格和更好的监视,以通过在团队中包括更多的技术专家来监视/审核DC和DRS,从而最大程度地降低数据服务风险。
DC和DRS管理的主要挑战与期望
样本银行的首席技术官就高层管理人员,孟加拉银行和BIBM的挑战和期望发表了意见。意见归纳如下。
一般挑战
1.为DC和DRS的基础设施开发分配适当的预算。
2.对专业人员进行适当的培训。
3.实施业务连续性计划。
4.合格的IT专业人员和审核员的可用性。
5.在DC和DRS中实现适当的IT安全性。
6. IT风险管理。
7.电源管理。
8.网络连接性和安全性。
9.缺乏快速的政策和决策制定能力。
10.系统漏洞访问工具和操作指南的可用性。
11. DC和DRS的标准化(按照ISO,BS等的指南)。
12. DRS的实时可用性13.地震和火灾风险。
14.提高员工的ICT安全意识。

孟加拉国银行(BB)的期望
1.中央银行可以定期更新“定期银行和金融机构信息和通信技术指南”并发布新版本。
2.在BB的监督下,可以开发一个通用的数据中心和灾难恢复站点,并由所有银行共享。
3.必须确保对BB进行密切监控。
4.孟加拉国银行可以安排有关DC和DRS管理的当前/新兴主题的研讨会。
5.有必要提高BB的IT审核员的专业知识。
6.需要提供基于风险的IT审计的详细指南。
7.情况正在改善,但没有达到应有的速度。中央银行应找出改善方法。
8.由印度储备银行开发的专门的电子银行培训机构,例如“银行技术发展与研究研究所(IDRBT,www.idrbt.ac.in)”,以进行高质量的银行技术IT培训和研究可以为所有商业银行设立
高层管理人员的期望
1.所有银行的管理层在IT投资/费用方面可能非常开放和自由,主要是为了使用最新的技术和设备升级DC和DRS。
2.管理层应确保假期和休假(包括休闲假期)的普通休假设施。
3.需要快速决策和制定政策。
4.银行应确保足够的人力并提供必要的培训。
5.应根据审计报告的建议采取纠正措施。
6.银行应将部分利润投资于DC和DRS的开发。
7.管理层可以认可IT部门的活动,并在必要时给予奖励。
BIBM的期望
1.可以开展更多有关银行DC和DRS管理的研究,培训,讲习班,研讨会。
2.可以定期向监管机构提供政策意见。
3.可以在高层管理人员和董事会之间建立意识,以改善银行的DC和DRS管理。
4. BIBM可能会像M. Sc。一样为银行的IT专业人员提供专门的培训和认证计划。电子银行或注册电子银行家。
意见和建议
一,我们发现所有银行的DC都建立在达卡。 DC和DRS的平均大小分别为2596和957平方英尺。 65%的CTO对DC和DRS的大小不满意。在有地震和火灾危险的高层建筑中,已经建立了约58%的DC和18%的DRS。另一方面,在达卡也建立了最大堤岸的DRS,距首都特区的平均空中距离为11.3公里,这表明发生自然灾害(如地震)的风险很高。在孟加拉国银行的CTO中,有38%的人认为该距离是科学标准的,而62%的人坚信该距离不足以避免发生自然灾害(例如地震)。此外,有35%的银行计划在单独的地震带中将其DRS远离DC。大约44%的银行还计划设置第二个DRS以降低风险。
在这方面,包括孟加拉银行在内的所有银行都可以做出特别决定。
第二,可以看出DRS的测试并不令人满意。只有66%的银行会定期对其进行测试,而总银行中的55%则害怕通过随时关闭数据中心来测试灾难恢复站点。所有测试DRS的银行都定期未能提供有关此问题的适当文件。如果发生任何灾难,此发现不支持数据的高可用性。
通过增加测试频率,银行应确保定期进行测试。中央银行和银行本身可以在这方面增加审计和检查的频率。
第三,崩溃时日志多路复用和归档对数据库非常重要。在这种紧急情况下,如果正确维护存档和日志文件,则数据库的自动恢复过程可能会确保“ 0位”丢失。此外,那些没有数据库复制和群集技术的用户在发生火灾或地震等灾难时可能无法恢复其数据,这显示出很高的数据恢复风险。发现只有46%的存储库确保了日志多路复用技术,而32%的存储库具有存档机制。
集中式在线银行的CTO应确保采用日志多路复用和归档技术,以确保数据“零位”丢失。
第四,关于孟加拉国银行通过DC和DRS降低数据服务风险的总体作用的总体看法,有45%的银行表示非常好,有55%的银行被评为良好,要求孟加拉国银行发挥更多和高质量的作用。孟加拉银行通常每年访问一次不同商业银行的DC和DRS。所有CTO都认为这还不够;频率应该增加。
孟加拉银行应聘请具有新技术知识的专家来更新其审计质量。孟加拉银行的ICT指南应定期更新,发布新版本,以确保正确实施。
五,所有银行的CTO都要求为所有商业银行建立一个包括数据库在内的部门/部门。这将有助于收集和共享有关孟加拉国银行业的现状,增长以及DC和DRS问题的最新信息。值得一提的是,印度储备银行已经成立了一个名为“银行技术发展与研究机构(IDRBT,www.idrbt.ac.in)”的研究所,作为进行银行业高质量IT培训和研究的自治中心。
孟加拉国可以成立一个工作队,以研究建立此类研究所的相关问题。孟加拉银行和BIBM可以在这方面采取主动。可以在BIBM设立一个电子银行研究小组。
第六,发现银行业忽视了IT培训,尽管这是一个至关重要的问题。大约3%的IT预算用于培训目的,而66%的IT主管对此问题不满意。约有44%的CTO提到,他们在面对巨大需求时未能为运营DC和DRS的员工提供足够的培训。
银行应为此提供所需的预算。混合计划可以由供应商(IBM,Oracle,Microsoft,Cisco等),不同银行的专业IT专业人员以及不同机构的院士共同安排。银行的IT专业人员的专门培训和认证计划可能由BIBM像M. Sc。进行。电子银行或注册电子银行家。
第七,Uptime Institute将DC分为四个类别。第1层规定的年度中断时间最多为28.8小时;第2层指定22个小时;第3层指定1.6个小时,第4层指定仅0.4个小时的年度中断,即99.995%的可用性。我们发现57%的DC属于1级,其余43%属于2级。然而,没有一家银行达到第三级或第四级类别。
缺乏长期的远见,计划和举措;银行的主要问题是人力短缺,IT预算不佳,电力危机,供应商反应迟钝,采购流程延迟以及缺乏高级培训。为了克服这些问题,每家银行都应拥有合格的ICT预算
| Class | maximum particles/m3 | FED STD 209E equivalent |
|||||
| >=0.1 µm | >=0.2 µm | >=0.3 µm | >=0.5 µm | >=1 µm | >=5 µm | ||
| ISO 1 | 10 | 2 | |||||
| ISO 2 | 100 | 24 | 10 | 4 | |||
| ISO 3 | 1,000 | 237 | 102 | 35 | 8 | Class 1 | |
| ISO 4 | 10,000 | 2,370 | 1,020 | 352 | 83 | Class 10 | |
| ISO 5 | 100,000 | 23,700 | 10,200 | 3,520 | 832 | 29 | Class 100 |
| ISO 6 | 1,000,000 | 237,000 | 102,000 | 35,200 | 8,320 | 293 | Class 1,000 |
| ISO 7 | 352,000 | 83,200 | 2,930 | Class 10,000 | |||
| ISO 8 | 3,520,000 | 832,000 | 29,300 | Class 100,000 | |||
| ISO 9 | 35,200,000 | 8,320,000 | 293,000 | Room Air | |||
| maximum particles/m3 | |||||
| Class | >=0.5 µm | >=1 µm | >=5 µm | >=10 µm | >=25 µm |
| Class 1 | 3,000 | 0 | 0 | 0 | |
| Class 2 | 300,000 | 2,000 | 30 | ||
| Class 3 | 1,000,000 | 20,000 | 4,000 | 300 | |
| Class 4 | 20,000 | 40,000 | 4,000 |
||
contact us
联系我们






 24小时服务热线:400-160-6690
24小时服务热线:400-160-6690 电子邮箱:polly@cd-estt.com
电子邮箱:polly@cd-estt.com 企业QQ:945319528
企业QQ:945319528 成都市一环路南一段22号
成都市一环路南一段22号